DynamoDB to Opensearch
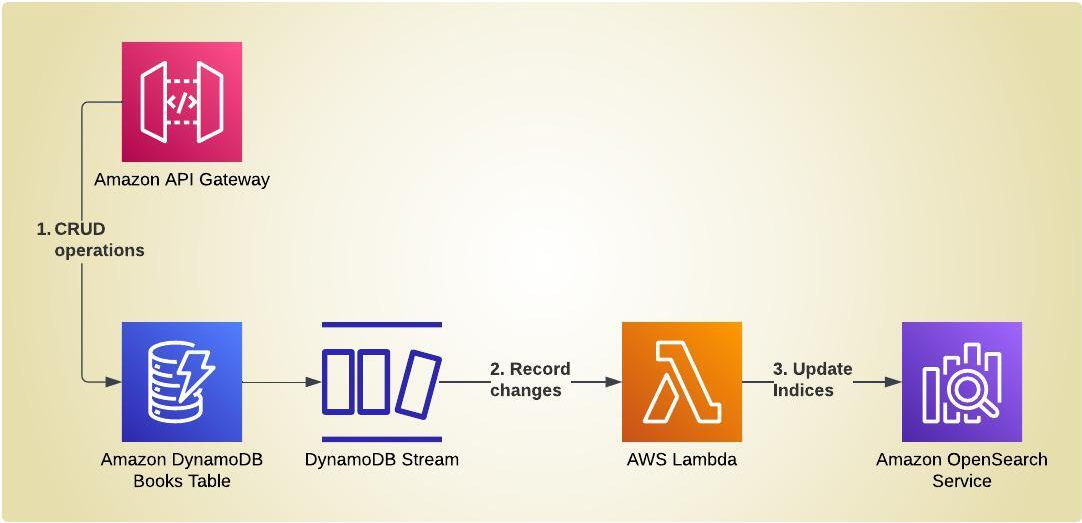
This project demonstrates how to automatically update indices in an Opensearch domain in response to CRUD operations against the source-of-truth database, in this case, DynamoDB. This keeps the Opensearch indices in sync with the DynamoDB table in near real-time.
Tech Stack
- Terraform / Terragrunt
- AWS Lambda, written in Python, deployed with Docker
- Amazon API Gateway
- Amazon DynamoDB
- Amazon Opensearch Service
The REST API and CRUD Operations
The scenario of a transactional application performing CRUD (Create, Read, Update and Delete) operations against a source of truth database is realized with a simple, Serverless application compose of a REST API for the CRUD functionality and a DynamoDB table as the database.
The REST API is implemented with Amazon API Gateway and OpenAPI. There is no “app” as such. The Rest API is directly integrated with the DynamoDB table using API Gateway exensions. This is reflects the agile way of starting out simple, only bringing in Lambdas in the case that there is more complex processing logic required between the API and database.
For example, the POST method integrated directly with the DynamoDB table using Velocity Template Language and API Gateway extensions in the OpenAPI spec as follows:
/books:
post:
x-amazon-apigateway-integration:
type: aws
uri: "arn:aws:apigateway:${aws_region}:dynamodb:action/PutItem"
httpMethod: POST
passthroughBehavior: when_no_match
credentials: ${apigw_role_arn}
requestTemplates:
application/json: |
#set($inputRoot = $input.path('$'))
{
"TableName": "${books_table_name}",
"Item": {
"book_id": { "S": "$context.requestId" },
"title": { "S": "$inputRoot.title" },
"author": { "S": "$inputRoot.author" }
}
}
responses:
default:
statusCode: 200
responseTemplates:
application/json: |
{
"message": "New book created."
"book_id": "$context.requestId"
}
Processing the Record Changes in DyanamoDB
The DynamoDB table Terraform resource has DynamoDB Streams enabled through which the changes as a result of CRUD operations are propagated:
resource "aws_dynamodb_table" "books" {
name = "${local.app_prefix}${terraform.workspace}-books"
billing_mode = "PAY_PER_REQUEST"
hash_key = "book_id"
attribute {
name = "book_id"
type = "S"
}
stream_enabled = true
stream_view_type = "NEW_IMAGE"
}
An aws_lambda_function resource and aws_lambda_event_source_mapping resource are defined in Terraform so that the DynamoDB change stream is the event source for the Lambda function:
resource "aws_lambda_function" "lambda_function" {
function_name = aws_ecr_repository.image_repo.name
role = aws_iam_role.lambda_role.arn
timeout = var.lambda_timeout
image_uri = docker_registry_image.image.name
package_type = "Image"
environment {
variables = {
OPENSEARCH_ENDPOINT = var.opensearch_endpoint
INDEX_NAME = var.index_name
}
}
}
resource "aws_lambda_event_source_mapping" "read_dynamodb_stream" {
event_source_arn = var.change_stream_arn
function_name = aws_lambda_function.lambda_function.function_name
starting_position = "LATEST"
}
The Lambda function processes the record changes and updates the OpenSearch indices in near-real-time. DELETES are removed from the OpenSearch indices, while UPDATES and INSERTS are upserted.
...
def handler(event, context):
logger.info(event)
client = OpenSearch(
hosts = [{'host': host, 'port': 443}],
http_auth = awsauth,
use_ssl = True,
verify_certs = True,
connection_class = RequestsHttpConnection
)
count = 0
if (event.get("Records", None) != None):
for record in event['Records']:
logger.info(f'DynamoDB Change Record: {record}')
if record['eventName'] == 'REMOVE':
id = record['dynamodb']['Keys']['book_id']['S']
logger.info(f'Removing document with id: {id}')
response = client.delete(
index = index,
id = id,
)
count += 1
logger.info(response)
else:
id = record['dynamodb']['Keys']['book_id']['S']
document = record['dynamodb']['NewImage']
logger.info(f'Indexing document: {document}')
response = client.index(
index = index,
body = document,
id = id,
refresh = True
)
count += 1
logger.info(response)
return f'{count} records processed.'
Infrastructure as Code with Terraform and Terragrunt
The application and databases are deployed with Terraform and Terragrunt. The Terraform is organized so that each logical unit (usually applicable to one AWS service) is its own Terraform module. For example, the Lambda module is organized in a file/folder structure as follows:
── artifacts
│ └── update_indices
│ ├── Dockerfile
│ ├── lambda
│ │ └── function.py
│ └── requirements.txt
├── backend.tf
├── data.tf
├── locals.tf
├── main.tf
├── providers.tf
└── variables.tf
The Terraform modules are then composed to make a comprehensive solution with Terragrunt. Terragrunt manages the dependencies between the Terraform modules and feeds the outputs of dependencies to the dependent project(s) as Terraform inputs.
For example, the Terragrunt file for the Lambda module needs the outputs of the API and OpenSearch modules which are declared as dependencies. The outputs of the API and OpenSearch modules are then fed as inputs to the Lambda module:
include {
path = find_in_parent_folders()
}
terraform {
source = "../../modules/lambda"
}
dependency "api" {
config_path = "../api"
mock_outputs = {
table_arn = "mock_table_arn_value"
change_stream_arn = "mock_change_stream_arn_value"
}
}
dependency "opensearch" {
config_path = "../opensearch"
mock_outputs = {
opensearch_endpoint = "mock_opensearch_endpoint_value"
}
}
inputs = {
aws_region = "us-west-2"
table_arn = dependency.api.outputs.table_arn
change_stream_arn = dependency.api.outputs.change_stream_arn
image_tag = 1
lambda_timeout = 30
opensearch_endpoint = dependency.opensearch.outputs.opensearch_endpoint
index_name = "books"
}
How I’ve laid things out here is a good example of how I like to approach a problem such as this - logical pieces that are composed to form a complex solution. I am also planning to use this approach as the foundation for updating OpenSearch indices for a DocumentDB song library in my Karaoke Project, which will definitely be a level of challenge above this one!
I arrived at this solution by piecing together the approaches from a couple other resources:
- The general approach and the code for the Lambda is taken from this article and then ported the code from Typescript to Python.
- The Terraform module organization with Terragrunt is an approach I learned on Pablo’s Spot YouTube channel, a standard Terraform / Terragrunt project structure that he favors on many of his projects.